

You know the scenario. A teammate asks you to add a feature to a module you've never touched. You open the file and... nothing makes sense. Variable names are cryptic. The logic jumps around without clear structure. There's no documentation, and the tests (if they exist) don't explain what the code is supposed to do. You could try to figure it out yourself, but that might take hours or days. So you do what everyone does: you interrupt the person who wrote it.
Except they're in a meeting, on vacation, or they left the company six months ago.
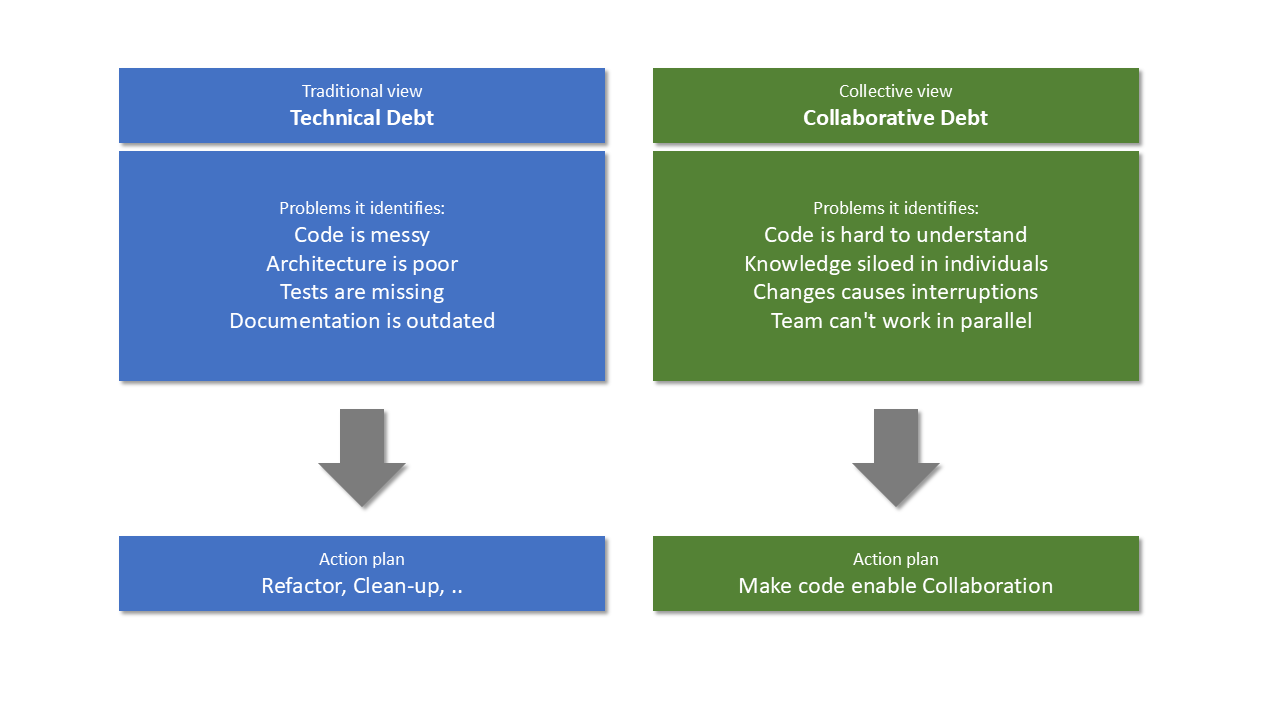
This is technical debt in action. But here's what we often miss: technical debt isn't just bad code. It's collaboration debt.
When code is unclear, every interaction requires explanation and negotiation. Knowledge becomes trapped in individuals' heads. Teams can't scale because every change requires finding the one person who "knows how it works." What we call technical debt is often code so unclear that working with it requires constant interruption to find the answer to question: "what does this do?"
This reframing matters because it changes how we think about code quality. It's not about perfectionism or ivory-tower principles. It's about whether your team can actually work together effectively.
The Daily Cost of Collaboration Debt
Let's look at what collaboration debt actually costs you.
Knowledge Silos: When People Become Single Points of Failure
Sarah is the only person who understands the payment processing module. Every change to billing, subscriptions, or invoicing requires Sarah's input. When Sarah goes on vacation, payment-related work stops. When Sarah eventually leaves for another company, the team faces weeks of archeology trying to understand code that should have been clear from the start.
This isn't Sarah's fault. It's a system design problem masked as a people problem. The code doesn't communicate its intent clearly enough for others to work with it independently. Sarah became irreplaceable because the code required constant interpretation.
Knowledge silos make teams fragile. They create bottlenecks. They make planning unpredictable because you can't parallelize work. Worse, they trap talented engineers in maintenance roles because nobody else can take over.
The Onboarding Nightmare
New engineers join your team excited to contribute. Instead, they spend weeks or months just trying to understand how things work. They ask questions constantly, but the answers aren't in the code, the documentation (if it exists) is outdated, and the only way to learn is through tribal knowledge passed down from senior engineers who themselves learned through painful trial and error.
I've seen teams where onboarding takes over six months before a new engineer can work autonomously. Not because the engineers lack talent, but because the codebase is a maze that requires a guide.
Good onboarding shouldn't depend on having the right person available to explain things. The code itself should communicate clearly enough that competent engineers can understand it independently, with documentation filling in context and architecture decisions.
Scaling Challenges: Why Adding Developers Doesn't Help
You'd think adding more developers would increase productivity proportionally. In practice, beyond certain team sizes, productivity per person often drops. The usual explanation is "coordination overhead," which is true but incomplete.
The real problem: when code is unclear, coordination becomes constant negotiation. Every interaction requires explaining what this module does, why it's structured this way, what assumptions it makes. Simple changes require discussions with multiple people because nobody is confident about side effects. Code reviews become interrogations rather than knowledge sharing.
I've worked on projects where changing a single function required coordinating with four different teams because nobody could confidently reason about the broader impact. Not because the system was inherently complex, but because the code didn't make its dependencies and contracts clear.
Clean, well-structured code reduces coordination needs. When modules have clear interfaces and responsibilities, teams can work in parallel with minimal interaction. When code is self-explanatory, developers can modify it confidently without constant consultation.
The Firefighting Trap
Some teams spend most of their time responding to production incidents rather than building new capabilities. These incidents often trace back to the same root cause: code that's too unclear to modify safely.
Someone makes a change. They don't fully understand the system (because it's not clear from the code). They miss a critical edge case or assumption. The change ships and breaks production. Now everyone drops what they're doing to firefight.
After the incident, there's rarely time to improve the underlying code quality. There's always another fire, another urgent feature, another deadline. The team is trapped in a cycle where poor code quality creates incidents, and constant firefighting prevents addressing quality.
When I've seen teams break this cycle, it's been through deliberately protecting time for quality improvements, even when it feels like there's no time. The teams that escape the firefighting trap recognize that quality debt is a collaboration problem: unclear code creates incidents because changes are risky and poorly understood.
Why This Problem Persists: A Brief History Lesson
If collaboration debt is so costly, why does every organization struggle with it?
The answer lies in how software development evolved. In the 1960s, when projects started failing at alarming rates, the industry recognized that software had grown beyond what individual programmers could manage alone. The 1968 NATO conference that popularized the term "software engineering" identified the core challenge: complexity had exceeded individual capacity.
More than fifty years later, we face the same fundamental problem at larger scale. Systems span millions of lines of code maintained by hundreds of developers across continents and time zones. Collaboration isn't optional; it is mandatory.
Yet business pressure constantly pushes for speed over clarity. "Just make it work, we'll clean it up later" becomes the mantra. But "later" never comes. The code you write today becomes the legacy code tomorrow's team inherits.
This creates a compounding problem. Unclear code makes changes risky and slow, which increases pressure to cut corners on the next feature, which makes the code even less clear. Complexity grows naturally without active management. Every new feature, integration, and edge case adds to the overall complexity.
The teams that manage this effectively treat code quality not as a nice-to-have but as a collaboration enabler. They recognize that the fastest way to go fast is to go well.
What Actually Helps: Practices That Enable Collaboration
So what does collaboration-friendly code look like? These aren't abstract principles; they're practical approaches that directly reduce collaboration overhead.
Clear Naming and Structure
Code should read like prose that explains what it does and why. Variables, functions, and classes should have names that make their purpose obvious. Structure should guide readers through the logic without requiring mental gymnastics.
This sounds obvious, but it's harder than it seems. Good naming requires thinking about your reader, not just what the computer needs. It means resisting abbreviations that save a few keystrokes but cost readers cognitive effort. It means organizing code so related concepts are grouped together and the flow matches how humans think about the problem.
When you inherit well-named, well-structured code, you can often understand it without documentation. The code itself communicates intent. When you need to modify it, you can confidently reason about where changes should go.
Tests as Living Documentation
Comprehensive tests serve two purposes. Obviously, they catch regressions when you modify code. Less obviously, they document expected behavior in a way that stays synchronized with the code because tests break when behavior changes.
When I encounter unfamiliar code with good test coverage, I start by reading the tests. They usually show me what the code is supposed to do, what edge cases it handles, what assumptions it makes. Tests are documentation that can't go stale because the continuous integration system enforces that they match reality.
Writing tests after the fact is painful. Writing tests alongside code (or before, if you practice test-driven development) is much more natural. But the value isn't just catching bugs. It's creating machine-verified documentation that future developers (including you) can trust.
Modular Architecture with Clear Interfaces
Good architecture isn't about following a specific pattern or framework. It's about organizing complexity so developers can work effectively without understanding the entire system.
Modules with clear, well-defined interfaces allow developers to treat internal implementation as a black box. You know what inputs the module accepts, what outputs it produces, and what guarantees it makes. You don't need to understand how it works internally to use it correctly.
This enables parallel work. Different developers or teams can work on different modules simultaneously with minimal coordination. It reduces cognitive load because you can focus on one module at a time. It makes changes safer because clear interfaces limit the blast radius of modifications.
The alternative is the "big ball of mud" where everything depends on everything else. Changing anything requires understanding how it affects dozens of other components. Nobody can work independently because there are no clear boundaries.
The Boy Scout Rule: Leave It Better Than You Found It
You can't fix all collaboration debt at once. Attempting massive rewrites rarely succeeds and usually makes things worse. What works is continuous, incremental improvement.
The Boy Scout Rule (from the scouting principle of leaving campsites cleaner than you found them) says: leave the code better than you found it. When you're working in a module, make small improvements. Clarify a confusing variable name. Extract a complex expression into a well-named function. Add a test for unclear behavior. Improve a misleading comment or add documentation where it's missing.
These small improvements compound over time. The codebase gradually becomes clearer, more testable, more maintainable. You're not blocked waiting for permission to "do a refactoring project." You're continuously improving collaboration infrastructure as part of normal work.
I've seen teams transform legacy codebases through disciplined application of the Boy Scout Rule. It takes months or years, not days or weeks. But it works because it's sustainable. You're not fighting against feature delivery; you're making feature delivery easier over time.
Code Review as Knowledge Sharing
Code review is often framed as quality control: catching bugs before they reach production. But its deeper value is knowledge sharing and collaboration practice.
When you review someone else's code, you're seeing how they think about problems, what patterns they use, what tradeoffs they make. When someone reviews your code, you get feedback on whether your intent is clear to others. Good code reviews ask questions like "Why did you choose this approach?" and offer suggestions like "This might be clearer if..."
This only works if code review is about learning and improving, not gatekeeping or showing off. The best code reviews I've participated in were conversations where both author and reviewer learned something. The worst were battles where reviewers nitpicked style while missing substantial issues.
For code review to enable collaboration, it needs to be timely (not a bottleneck), constructive (not adversarial), and focused on clarity and maintainability, not just correctness.
The Velocity Paradox: Quality Enables Speed
Here's the part that sounds counterintuitive but I've found to be true in practice: focusing on code quality makes you faster, not slower.
When code is clear and well-tested, changes are straightforward. You can confidently modify it because tests catch regressions. You can understand it quickly because it's well-structured. You can work in parallel because modules have clear boundaries.
When code is unclear and poorly tested, every change is risky and slow. You spend hours understanding what something does. You're afraid to modify it because you don't know what might break. You need to coordinate with multiple people because nobody is confident about side effects. You spend time firefighting production incidents caused by changes that seemed safe.
I've worked on teams that moved extremely fast by maintaining high quality standards. I've also worked on teams that moved slowly despite (or because of) constantly cutting quality corners. The difference isn't talent or methodology. It's recognizing that quality and velocity aren't trade-offs; quality enables sustainable velocity.
This doesn't mean gold-plating everything or pursuing perfection. It means caring enough about clarity and maintainability that your team can work together effectively. It means recognizing that unclear code creates collaboration overhead that compounds over time.
Looking Forward: AI and the Collaboration Imperative
As generative AI becomes integrated into development workflows, the need for clear, well-crafted code becomes—in my early experience—more critical, not less.
We're already seeing AI assistants that help write, review, and refactor code. These tools are most effective when working with code that's well-structured and clearly expresses its intent. When code is a tangled mess, AI suggestions are often off-target because the AI can't understand the unclear intent.
More fundamentally, as AI becomes a collaborator in the development process, your code needs to communicate clearly not just to human maintainers but to AI assistants that help evolve it. The same practices that make code readable for humans make it understandable for AI: clear naming, good structure, comprehensive tests, explicit interfaces.
We're not replacing human collaboration with AI. We're adding AI as another collaborator that needs to understand our code. This amplifies the importance of clarity and maintainability.
What This Means for You
If you're working on a team (and most of us are), you're already experiencing collaboration debt. The question is whether you're managing it or letting it grow.
Start noticing the collaboration costs in your daily work:
- How often do you interrupt teammates to ask what code does?
- How long does it take to onboard new team members?
- When you make changes, are you confident about the impact, or are you guessing?
- How much time do you spend firefighting versus building new capabilities?
These aren't just quality problems. They're collaboration problems. And they're addressable through deliberate practice: clearer code, better tests, modular architecture, continuous improvement.
You don't need permission to start. You can apply the Boy Scout Rule in your next pull request. You can write clearer tests for the next feature. You can structure your next module with better interfaces. You can make your next code review about learning and knowledge sharing.
Over time, these small improvements compound. The codebase becomes easier to work with. Collaboration overhead decreases. Velocity increases. Your team becomes more effective.
The fastest way to go fast is to go well. Not because quality is virtuous, but because quality enables collaboration, and collaboration is how modern software gets built.
Further Reading
For historical context on why complexity management matters:
- The 1968 NATO Software Engineering Conference report documents how complexity exceeded individual capacity
- Fred Brooks' "The Mythical Man-Month" explores why adding developers doesn't proportionally increase productivity
For practical approaches to managing technical debt:
- Martin Fowler's "Refactoring" provides patterns for continuous improvement
- Michael Feathers' "Working Effectively with Legacy Code" offers strategies for improving unclear codebases
For collaboration practices:
- Kent Beck's "Extreme Programming Explained" explores practices like test-driven development and pair programming
- Nicole Forsgren's "Accelerate" provides research on what high-performing teams do differently